本文最后更新于 2026-03-04T21:26:45+08:00
引言
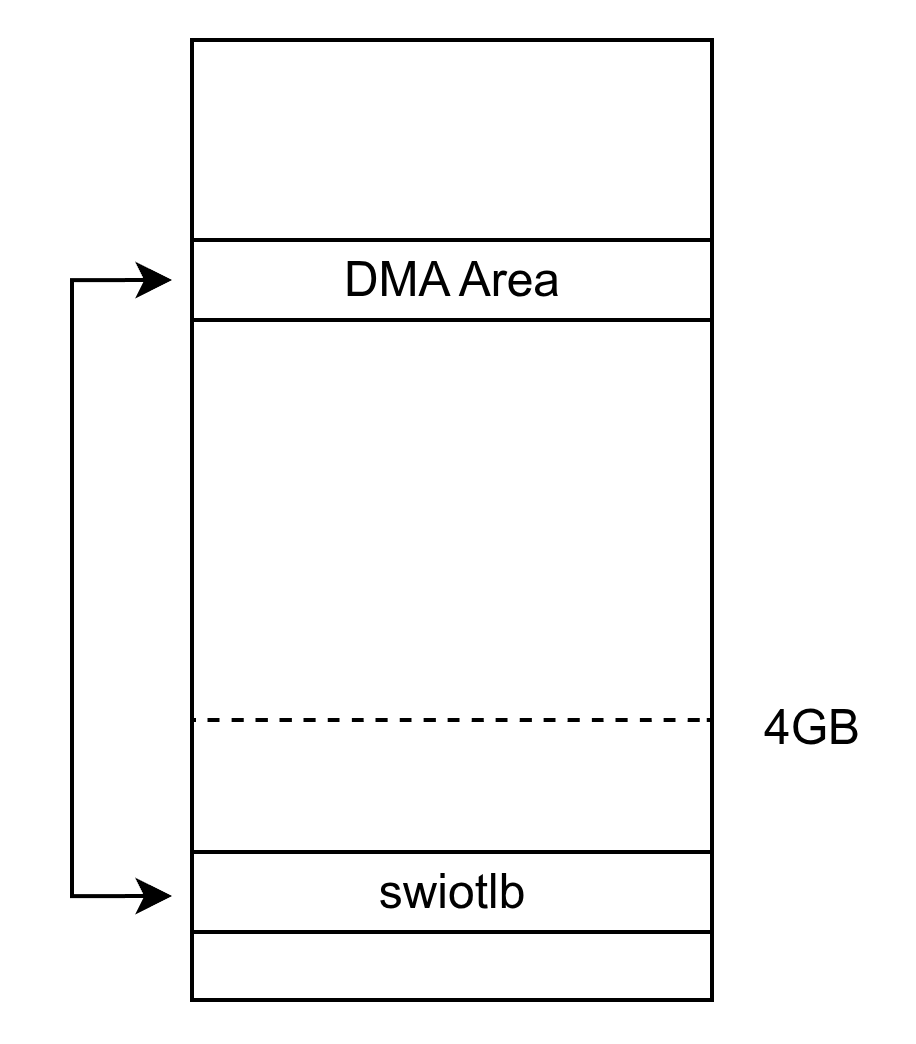
在操作系统由 32 位向 64 位过渡的过程中,面临许多兼容性问题。部分老旧的 DMA 设备只支持 32 位地址,在与新的 64 位系统交互时无法正常访问 4GB 以上的内存区域。
为了解决这一问题,Linux 引入了 swiotlb(Software I/O Translation Lookaside Buffer)机制。其核心原理是在物理地址空间 4GB 以下预先分配一块连续的内存区域,作为弹跳缓冲区(bounce buffer)。当旧设备需要访问超过 4GB 的内存区域时,CPU 会将数据从原始内存区域复制到这块弹跳缓冲区中,设备完成访问后,若数据发生了改变,CPU 再将数据从弹跳缓冲区同步回原始内存区域。
这就好像一个小孩想要拿到放在柜子上的玩具,但他最高只能拿到小桌子上的东西。于是他叫来了一个大人帮忙把玩具从柜子上拿下来放到小桌子上,这样小孩就能拿到玩具了。小孩玩完后,再由大人把玩具放回柜子上。
swiotlb 原理
寻址能力有限的 DMA 设备是比喻中的小孩,CPU 则是那个大人,负责在原始内存(柜子)和弹跳缓冲区(小桌子)之间搬运数据(玩具)。
随着硬件的发展,支持 64 位寻址的硬件和 IOMMU 已逐渐普及。作为过渡时期的兼容方案,swiotlb 本该随着旧设备的淘汰而逐渐淡出历史舞台。然而,新技术的兴起让 swiotlb 意外迎来了第二春。
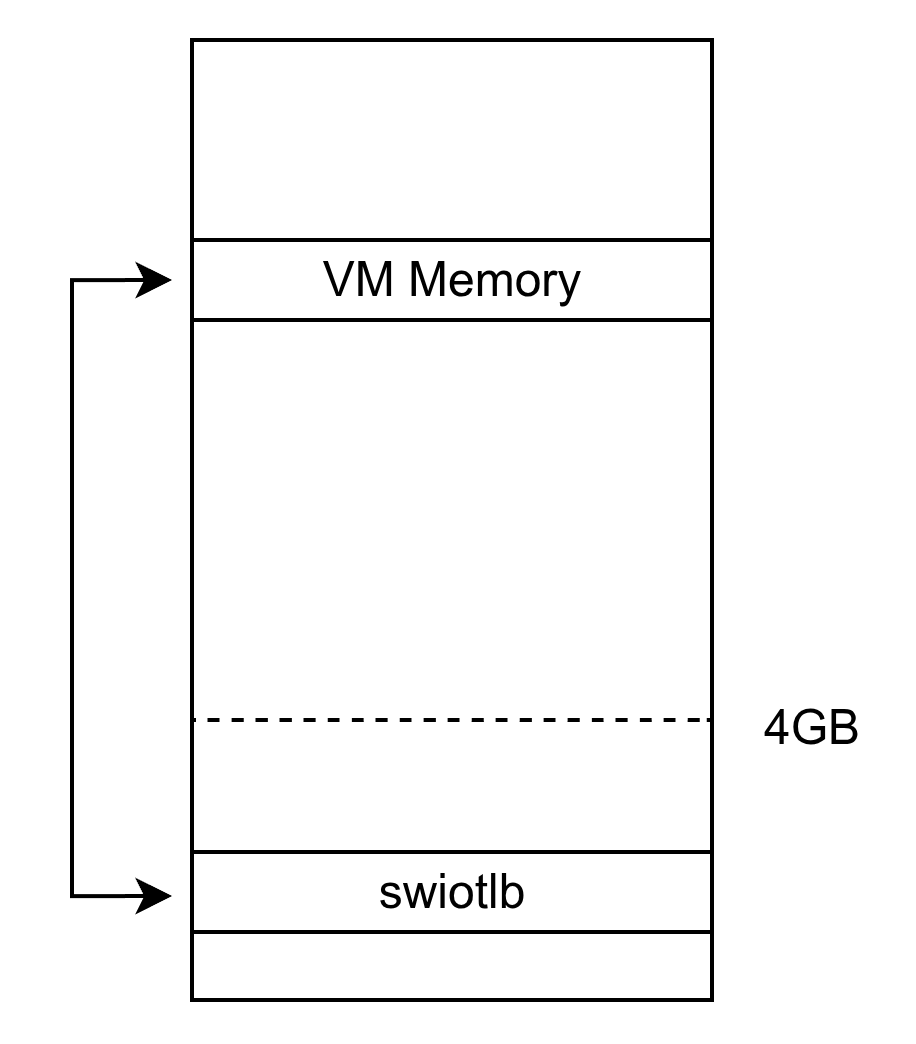
机密计算或受保护虚拟机场景下,虚拟机的内存是受保护的,宿主机和 Hypervisor 不能直接读取虚拟机内存。但在 IO 普遍采用半虚拟化的现实中,虚拟机需要宿主机帮忙完成各种 IO 操作,否则就无法正常运行。所以对于这些 IO 操作所涉及的内存区域,就需要一种方式让宿主机也能够访问到。于是,swiotlb 又派上了用场。
在机密计算的场景中,弹跳缓冲区其实没必要再放在 4GB 以下,但出于兼容性的考虑,swiotlb 仍然默认将其放在 4GB 以下。但可通过设置 SWIOTLB_ANY 标志允许其分配到任意位置。
swiotlb 的结构
swiotlb 的缓冲区是从一个或多个内存池(pool)中分配的。通常情况下,一个 swiotlb 分配器只有一个默认池,但如果启用 CONFIG_SWIOTLB_DYNAMIC,则可以动态创建多个池。
默认池在内核引导时预先分配,要求必须是一块物理上连续的内存区域,且这块区域只能作为 swiotlb 的 弹跳缓冲区使用。池默认分配在 4GB 地址以下。
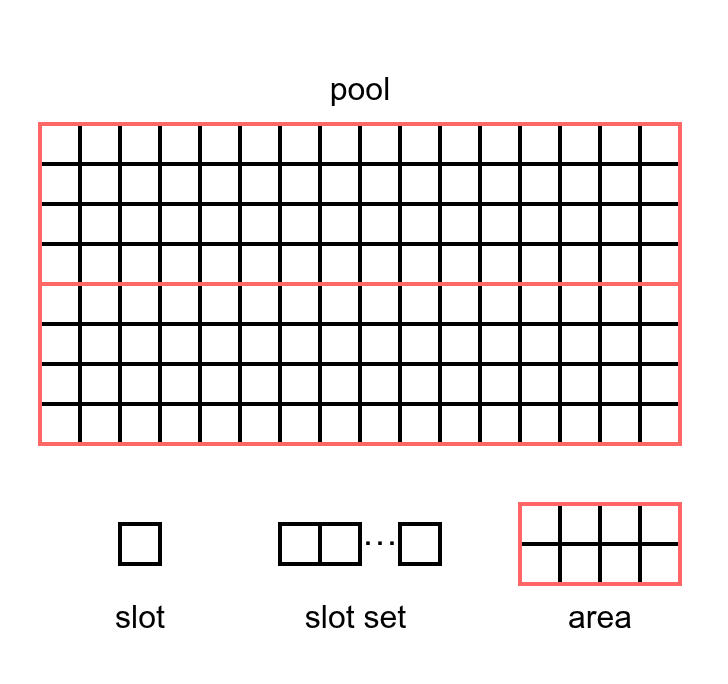
池的内部划分为若干相同大小的槽(slot),特定数量的槽构成一个槽组(slot set)。同时,池又被划分为若干区域(area)。
这四种结构的关系如下图所示,图中一个小方块代表一个槽,一行槽构成一个槽组,红框代表一个区域,池则是上述结构构成的整体。
swiotlb 的结构
缓冲区的分配需要遵循以下规则:
缓冲区分配的最小单位是槽,一个槽只能分给一个缓冲区,绝不会出现两个缓冲区共用一个槽的情况;
缓冲区只能在同一槽组中分配,因此一个槽组的大小就是单个缓冲区的最大大小;
缓冲区的分配不能跨区域;
缓冲区的分配是连续的。
单个槽的大小由 IO_TLB_SIZE 宏决定,默认为 2KB。
一个槽组中的槽数为 IO_TLB_SEGSIZE 个,默认为 128 个。因此默认情况下弹跳缓冲区的最大大小为 256KB,这意味着在使用 swiotlb 的情况下,单次 DMA 传输的最大数据量不能超过 256KB。
swiotlb 默认池的大小是 IO_TLB_DEFAULT_SIZE,默认为 64MB。
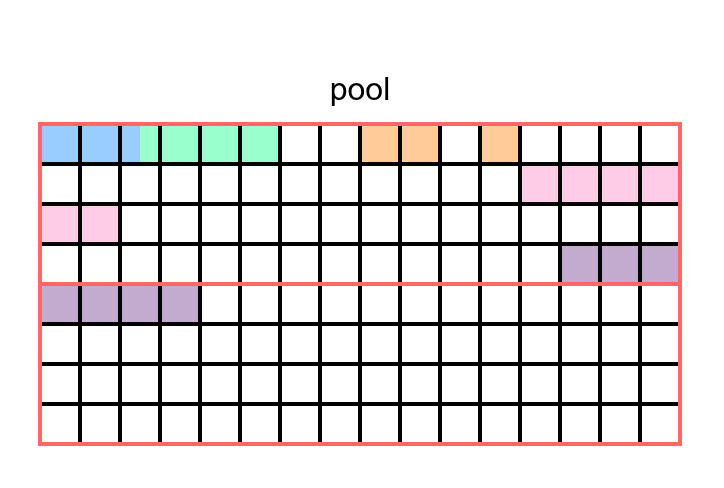
用一种颜色代表一次缓冲区分配所占用的槽,下图中的分配情况都是不可能的。
蓝色和绿色:两次分配共用了一个槽。
橙色:分配不连续。
粉色:分配不在同一槽组内。
紫色:分配不在同一槽组 / 区域内。
错误的分配方式
swiotlb 的核心 API 是 swiotlb_tbl_map_single() 和 swiotlb_tbl_unmap_single(),其原理十分简单。
swiotlb_tbl_map_single() 先在内存池中查找满足请求大小的可用空间分配缓冲区,然后将原始内存的内容复制到缓冲区中。
swiotlb_tbl_unmap_single() 则是反过来,先将缓冲区的内容复制到原始内存,随后再解除缓冲区的分配。
但实际上并不会直接使用这两个函数,所有 swiotlb 相关的操作都集成在 DMA API 中。如果设备需要,DMA API 会自动调用函数来完成 swiotlb 相关的操作。
核心数据结构
swiotlb 相关的核心数据结构有四个:io_tlb_mem、io_tlb_pool、io_tlb_area 和 io_tlb_slot。
io_tlb_mem 代表一个 swiotlb 内存分配器,包含内存池和相关的元数据。
1 2 3 4 5 6 7 8 struct io_tlb_mem {struct io_tlb_pool defpool ;unsigned long nslabs; bool force_bounce; bool for_alloc;
io_tlb_pool 表示一个内存池,包含一些元信息以及区域和槽的数组。
1 2 3 4 5 6 7 8 9 10 11 12 struct io_tlb_pool {phys_addr_t start; phys_addr_t end; void *vaddr; unsigned long nslabs; unsigned int nareas; unsigned int area_nslabs; struct io_tlb_area *areas ;struct io_tlb_slot *slots ;
io_tlb_slot 代表一个槽位。
1 2 3 4 5 struct io_tlb_slot {phys_addr_t orig_addr; size_t alloc_size; unsigned int list ;
假设 IO_TLB_SIZE=2KB,弹跳缓冲区对应于起始地址为 A,长度为 L 字节的内存区域,L/2KB=N。则这块缓冲区中槽位的字段值如下表所示:
orig_addr
A
A+2048
A+4096
…
A+2048*(N-1)
alloc_size
L
L-2048
L-4096
…
L-2048*(N-1)
list
0
0
0
…
0
已被占用的槽位的 list 字段均为 0。
下图展示了 list 字段的取值方式。蓝色方块代表被占用的槽位,白色方块代表空闲槽位,方块中的数字为槽位 list 字段的值。
list 字段的取值方式
io_tlb_area 代表一个区域,每个区域有自己独立的自旋锁。
1 2 3 4 5 struct io_tlb_area {unsigned long used; unsigned int index; spinlock_t lock;
index 字段是为了避免每次都从头开始查找空闲槽位,提升查找效率。
工作流程
这一小节结合 Linux 6.6 内核源码介绍 swiotlb 的工作流程。
初始化
内核支持 swiotlb=[NSLABS][,NAREAS][,force|noforce] 格式的启动参数。
NSLABS 参数指定内存池中的槽数。NAREAS 参数指定默认区域个数。force 强制启用 swiotlb,noforce 禁用 swiotlb
默认的 swiotlb 内存分配器 io_tlb_default_mem 是一个静态变量,它在 swiotlb_init_remap 函数中进行初始化,该过程在内核启动的极早期完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 void __init swiotlb_init_remap (bool addressing_limit, unsigned int flags, int (*remap)(void *tlb, unsigned long nslabs)) struct io_tlb_pool *mem =unsigned long nslabs;unsigned int nareas;size_t alloc_size;void *tlb;if (!addressing_limit && !swiotlb_force_bounce)return ;if (swiotlb_force_disable)return ;if (!default_nareas)while ((tlb = swiotlb_memblock_alloc(nslabs, flags, remap)) == NULL ) {if (nslabs <= IO_TLB_MIN_SLABS)return ; 1 , IO_TLB_SEGSIZE);sizeof (*mem->slots), nslabs));sizeof (struct io_tlb_area),false , nareas);
在 swiotlb_init_io_tlb_pool 函数中进一步初始化了内存池结构体的各项元数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 static void swiotlb_init_io_tlb_pool (struct io_tlb_pool *mem, phys_addr_t start, unsigned long nslabs, bool late_alloc, unsigned int nareas) void *vaddr = phys_to_virt(start);unsigned long bytes = nslabs << IO_TLB_SHIFT, i;for (i = 0 ; i < mem->nareas; i++) {0 ;0 ;for (i = 0 ; i < mem->nslabs; i++) {list = min(IO_TLB_SEGSIZE - io_tlb_offset(i),0 ;memset (vaddr, 0 , bytes);return ;
映射
swiotlb 的映射有两条路径。
第一条路径用于映射线性内存区域:
1 2 3 4 5 6 dma_map_single()
第二条路径用于映射 scatterlist(多个分散的内存片段):
1 2 3 4 5 6 7 8 dma_map_sg()
但两条路径最终都会调用 swiotlb_map。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 dma_addr_t swiotlb_map (struct device *dev, phys_addr_t paddr, size_t size, enum dma_data_direction dir, unsigned long attrs) phys_addr_t swiotlb_addr;dma_addr_t dma_addr;0 , dir,if (swiotlb_addr == (phys_addr_t )DMA_MAPPING_ERROR)return DMA_MAPPING_ERROR;if (!dev_is_dma_coherent(dev) && !(attrs & DMA_ATTR_SKIP_CPU_SYNC))return dma_addr;
swiotlb_tbl_map_single 函数中的核心操作是查找空闲槽位,分配弹跳缓冲区和数据拷贝。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 phys_addr_t swiotlb_tbl_map_single (struct device *dev, phys_addr_t orig_addr, size_t mapping_size, size_t alloc_size, unsigned int alloc_align_mask, enum dma_data_direction dir, unsigned long attrs) struct io_tlb_mem *mem =unsigned int offset = swiotlb_align_offset(dev, orig_addr);struct io_tlb_pool *pool ;unsigned int i;int index;phys_addr_t tlb_addr;if (index == -1 ) {if (!(attrs & DMA_ATTR_NO_WARN))"swiotlb buffer is full (sz: %zd bytes), total %lu (slots), used %lu (slots)\n" ,return (phys_addr_t )DMA_MAPPING_ERROR;for (i = 0 ; i < nr_slots(alloc_size + offset); i++)return tlb_addr;
查找可用槽位
查找相关的函数有三个,调用结构如下:
1 2 3 swiotlb_find_slots()
swiotlb_find_slots 是 swiotlb_pool_find_slots 的简单包装,重点关注后两个函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 static int swiotlb_pool_find_slots (struct device *dev, struct io_tlb_pool *pool, phys_addr_t orig_addr, size_t alloc_size, unsigned int alloc_align_mask) int start = raw_smp_processor_id() & (pool->nareas - 1 );int i = start, index;do {if (index >= 0 )return index; if (++i >= pool->nareas)0 ; while (i != start); return -1 ;
在给 start 赋值时给每个 CPU 优先指定了一个特定的查找区域,巧妙实现了区域的负载均衡,减少了锁竞争。
raw_smp_processor_id() 是当前 CPU 的 id,由于 nareas 是 2 的幂,所以整个与运算相当于 cpu_id mod nareas。
0 号 CPU 会首先从区域 0 开始查找,1 号 CPU 则从区域 1 开始查找,以此类推。只有当自己的起始区域无可用槽位时 CPU 才会去其他的区域查找,这就降低了多个 CPU 竞争同一个区域锁的可能。
swiotlb_area_find_slots 中的代码相对复杂一些。为便于理解,在注释前加了字母编号,稍后会在讲解中引用。函数先遍历检查槽位是否满足对齐条件,是否有足够空间,找到合适的槽位后则更新槽位的元数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 static int swiotlb_area_find_slots (struct device *dev, struct io_tlb_pool *pool, int area_index, phys_addr_t orig_addr, size_t alloc_size, unsigned int alloc_align_mask) struct io_tlb_area *area =unsigned long boundary_mask = dma_get_seg_boundary(dev);dma_addr_t tbl_dma_addr =unsigned long max_slots = get_max_slots(boundary_mask);unsigned int iotlb_align_mask = dma_get_min_align_mask(dev);unsigned int nslots = nr_slots(alloc_size), stride;unsigned int offset = swiotlb_align_offset(dev, orig_addr);unsigned int index, slots_checked, count = 0 , i;unsigned long flags;unsigned int slot_base;unsigned int slot_index;1 );if (alloc_size >= PAGE_SIZE)1 );if (unlikely(nslots > pool->area_nslabs - area->used))goto not_found;for (slots_checked = 0 ; slots_checked < pool->area_nslabs; ) {phys_addr_t tlb_addr;if ((tlb_addr & alloc_align_mask) ||1 );continue ;if (!iommu_is_span_boundary(slot_index, nslots,if (pool->slots[slot_index].list >= nslots)goto found;return -1 ;for (i = slot_index; i < slot_index + nslots; i++) {list = 0 ;for (i = slot_index - 1 ;1 &&list ; i--)list = ++count;return slot_index;
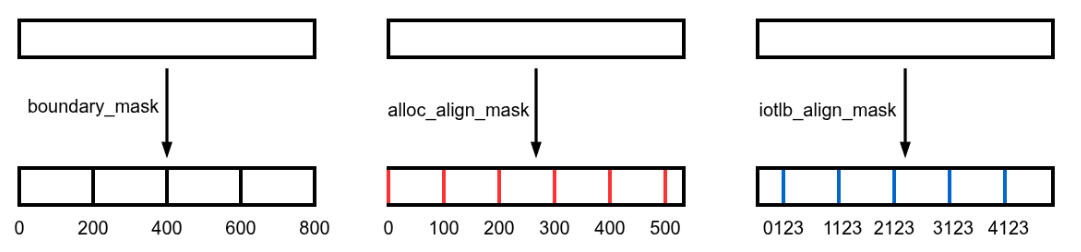
函数中涉及到三个边界和对齐的约束:
boundary_mask: 限制边界;alloc_align_mask: 要求对齐;iotlb_align_mask: 要求地址低位和原地址保持一致。
boundary_mask 为内存区域设立了边界,形成若干小区域。分配只允许在同一区域内进行,禁止跨越边界。如下图所示,boundary_mask=0x1FF 时,只能在 00x200,0x200 0x400 等范围内分配缓冲区。之前提到过单次分配的最大空间是一个槽组的大小,但 boundary_mask 可能进一步限制此大小(见注释 A)。
边界和对齐约束(图中地址均为十六进制)
alloc_align_mask 和 iotlb_align_mask 限定了分配只能在特定位置开始(在图中分别用红色和蓝色竖线表示)。
其中,alloc_align_mask 要求按掩码对齐,即要求分配起始地址的掩码位为 0。如 alloc_align_mask=0xFF,则只能在 0,0x100,0x200 等位置开始分配。由于缓冲区最小的分配单位是槽,所以分配起始地址至少要与槽位对齐(注释 B)。
iotlb_align_mask 要求分配起始地址的低位和原始地址保持一致。如原始地址以 0x123 结尾, iotlb_align_mask=0xFFF,则只能在同样以 0x123 结尾的地址上分配。
注意,alloc_align_mask 和 iotlb_align_mask 的要求可能存在冲突,上面就是一个例子。在这种情况下,优先遵循 alloc_align_mask 的对齐要求,同时尽可能保留 iotlb_align_mask 的约束。根据注释 C 的代码,iotlb_align_mask 的限制会放宽到 0xF00,只要求 8~11 位与原地址相同即可。
槽位先后经历三次检查:
对齐检查(注释 D)
边界检查(注释 E)
空间检查(注释 F)
槽位在未通过对齐检查时,会继续检查紧接着的下一个槽位。
槽位通过对齐检查但未通过后续检查时,会跳跃 stride 个槽位,继续检查下一个满足对齐要求的槽位。
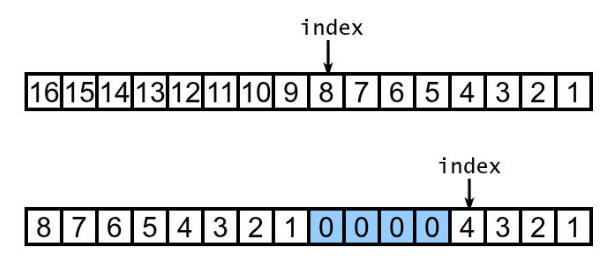
当找到合适的槽位后,需要更新元数据。这主要分两个步骤,对应于代码中的两个 for 循环。
如下图所示,index 指向当前的查找位置,需要分配 4 个槽位的缓冲区。第一个循环更新本次分配为缓冲区的槽位(下图中蓝色的槽位)。由于缓冲区前还有其他的空闲槽位,它们的 list 字段也需要更新,这就对应于第二个循环。
映射时槽位元数据的更新过程
最后,更新下次查找的起点(index)和区域已占用槽数。空闲槽位的查找和缓冲区的分配至此完成。
数据拷贝
数据拷贝通过 swiotlb_bounce 函数完成,主要的参数有:
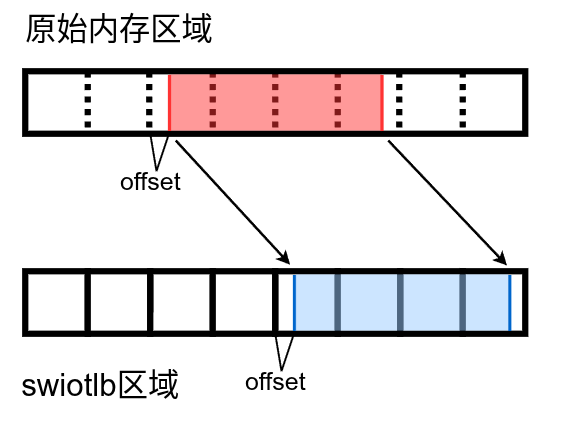
tlb_addr:弹跳缓冲区内的物理地址,这是请求拷贝(到)的起始位置。该地址不一定与槽位边界对齐,可能有偏移。size:要拷贝的数据长度。dir:数据相对于设备的流向,可以是
DMA_TO_DEVICE:设备要从缓冲区读数据,需要将原始数据拷贝到缓冲区。DMA_FROM_DEVICE:设备要向缓冲区写数据,需要将缓冲区数据同步到原始内存。 数据不一定完全占满整个槽位,可能存在偏移。如图弹跳缓冲区占用了 4 个槽位,但在第一个槽位和第四个槽位中都有无数据的部分。
数据拷贝的对应关系
swiotlb_bounce 首先会对 tlb_addr 的有效性进行检查,防止访问到槽位中无有效数据的部分,之后再进行数据拷贝。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 static void swiotlb_bounce (struct device *dev, phys_addr_t tlb_addr, size_t size, enum dma_data_direction dir) struct io_tlb_pool *mem =int index = (tlb_addr - mem->start) >> IO_TLB_SHIFT; phys_addr_t orig_addr = mem->slots[index].orig_addr; size_t alloc_size = mem->slots[index].alloc_size; unsigned long pfn = PFN_DOWN(orig_addr);unsigned char *vaddr = mem->vaddr + tlb_addr - mem->start; unsigned int tlb_offset, orig_addr_offset;if (orig_addr == INVALID_PHYS_ADDR)return ;1 ); if (tlb_offset < orig_addr_offset) {1 ,"Access before mapping start detected. orig offset %u, requested offset %u.\n" ,return ;if (tlb_offset > alloc_size) {1 ,"Buffer overflow detected. Allocation size: %zu. Mapping size: %zu+%u.\n" ,return ;if (size > alloc_size) {1 ,"Buffer overflow detected. Allocation size: %zu. Mapping size: %zu.\n" ,if (PageHighMem(pfn_to_page(pfn))) {unsigned int offset = orig_addr & ~PAGE_MASK; struct page *page ;unsigned int sz = 0 ;unsigned long flags;while (size) {min_t (size_t , PAGE_SIZE - offset, size); if (dir == DMA_TO_DEVICE)else 0 ; else if (dir == DMA_TO_DEVICE) {memcpy (vaddr, phys_to_virt(orig_addr), size);else {memcpy (phys_to_virt(orig_addr), vaddr, size);
解除映射
在理解了映射的过程后,再来看解除映射就十分简单了。
首先如果映射是 DMA_FROM_DEVICE 方向,需要将缓冲区的内容同步到原始内存中。之后调用 swiotlb_release_slots 清理元数据。
1 2 3 4 5 6 7 8 9 10 11 void swiotlb_tbl_unmap_single (struct device *dev, phys_addr_t tlb_addr, size_t mapping_size, enum dma_data_direction dir, unsigned long attrs) if (!(attrs & DMA_ATTR_SKIP_CPU_SYNC) &&
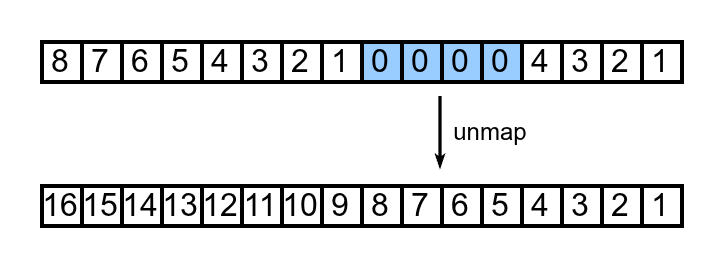
更新元数据的过程和分配时类似。
解除映射时槽位元数据的更新过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 static void swiotlb_release_slots (struct device *dev, phys_addr_t tlb_addr) struct io_tlb_pool *mem =unsigned long flags;unsigned int offset = swiotlb_align_offset(dev, tlb_addr);int index = (tlb_addr - offset - mem->start) >> IO_TLB_SHIFT;int nslots = nr_slots(mem->slots[index].alloc_size + offset);int aindex = index / mem->area_nslabs;struct io_tlb_area *area =int count, i;if (index + nslots < ALIGN(index + 1 , IO_TLB_SEGSIZE))list ;else 0 ;for (i = index + nslots - 1 ; i >= index; i--) {list = ++count;0 ;for (i = index - 1 ;1 && mem->slots[i].list ;list = ++count;
受限 DMA 池
受限 DMA 池是独立于默认 swiotlb 的内存池,作为特定设备的专用内存区域。每个受限池有独立的 io_tlb_mem 结构。
受限池功能可通过 CONFIG_DMA_RESTRICTED_POOL 配置启用。
受限池由设备树指定。相较于普通的 swiotlb 池,受限池新增了 swiotlb_alloc 和 swiotlb_free 两个 API,用于直接从池中分配和释放内存页面,而非复制已有内存。
受限 DMA 池的主要作用是增强 DMA 操作的安全性。
在没有 IOMMU 的系统上,DMA 设备拥有对系统内存的完全访问能力。设备固件的漏洞可能导致任意内存读写。受限池配合可信固件可将 DMA 操作限制在一个预留区域内,避免设备随意访问内存。
IOMMU 虽然提供地址转换和访问控制,但以页面为粒度(通常 4KB)。设备若只需 100 字节数据,IOMMU 仍需允许整个页面访问,页面内其他部分可能包含无关的内核数据。受限池则可通过 swiotlb 机制精确复制需要的数据到弹跳缓冲区,防止设备越界读取。
在受保护虚拟机中,虚拟机内存受到加密或权限控制的保护,对 Hypervisor 和设备不可见,但某些设备需要进行 DMA。在这种情况下,受限池可以充当不受保护的数据中转区域。虚拟机将需要提供给设备的数据解密后复制到受限池中,设备从受限池中读取数据。这既保护了 VM 内存的完整性,也保证了设备能正常工作。
一些优化尝试
swiotlb 作为一个过渡方案,在设计之初并未太多考虑性能问题。但在机密计算时代,swiotlb 的低效成为一个严重的瓶颈,swiotlb 成为性能优化的一个重点区域,多区域机制就是在此时期引入的。本节总结了我在工作中遇到的一些问题、解决方案和资料。
当出现 swiotlb buffer is full 警告时,可能是内存池被基本占满找不到空闲槽位或者单次传输的数据量超过了槽组大小(默认 256KB)。
第一种情况可以在内核启动参数中设置更大的内存池总槽数。如 swiotlb=65536,在槽大小为 2KB 的情况下,这是 128MB。
第二种情况则需要增大内核源码中 IO_TLB_SEGSIZE 的值,重新编译安装内核。
受限 DMA 池初始化时用 kcalloc() 分配槽位的元数据,而 kcalloc() 限制分配的大小最大为 4MB。如果受限池大小设为 342MB,每 2K 需要一个 24 字节的 io_tlb_slot 结构,总共就需要 4.0078MB 内存,超过了分配大小限制。在运行虚拟机时此问题表现为段错误。
如果要设置大于 342MB 的受限 DMA 池,需要将 rmem_swiotlb_device_init 函数中 pool->slots 对应的 kcalloc 和 kfree 替换为 kvcalloc 和 kvfree。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 static int rmem_swiotlb_device_init (struct reserved_mem *rmem, struct device *dev) if (!mem) {struct io_tlb_pool *pool ;sizeof (*mem), GFP_KERNEL);if (!mem)return -ENOMEM;sizeof (*pool->slots), GFP_KERNEL);if (!pool->slots) {return -ENOMEM;sizeof (*pool->areas),if (!pool->areas) {return -ENOMEM;
论文 Measuring and Optimizing the Performance of the Android Virtualization Framework 在 swiotlb 内存池上叠加了一层缓存,尝试解决 swiotlb 在引进多区域机制前的锁竞争问题。
每个 CPU 拥有 13 个空闲列表作为缓存层,每个列表存放固定大小的内存块,块大小按 2 的幂次方排列 (即 \(2^0, 2^1, ..., 2^{12}\) 字节) 。为了避免 \(O(n)\) 的搜索,每个空闲列表使用环形缓冲区来管理。这使得申请和释放操作都能在 \(O(1)\) 常数时间内完成。
系统引入了多级锁机制,为每个 CPU 区域下的每个特定大小列表分配独立锁。在分配缓冲区时,CPU 首先尝试从本地缓存列表分配;若失败,则尝试从其他 CPU 的缓存中分配空闲块;最后才回退到原始的全局共享内存池中进行搜索。
实验显示该优化在小数据量、高频次的 I/O 场景(如网络传输)下性能提升显著,因为此类场景对分配延迟和锁竞争极其敏感;而在大数据量的磁盘 I/O 场景下,由于单次传输耗时较长且更受限于带宽瓶颈,缓存带来的分配效率提升相对有限。
在当前的设计中,槽位使用 list 来追踪空闲槽位数量。在分配或释放缓冲区时,前面的空闲槽位也要更新 list 的值。曾有建议改用位图来记录槽位的占用情况 ,这个补丁曾被 ubuntu-azure 临时采用 ,但最终并未合入主线。
总结
从技术演进的角度看,swiotlb 最初只是一个为了兼容老旧 32 位 DMA 设备而设计的过渡方案 。但在机密计算和受保护虚拟机(如 pKVM)兴起的今天,由于宿主机无法直接访问受保护的虚拟机内存,swiotlb 意外地成为了数据交换的关键安全枢纽 。
目前社区仍在不断优化 swiotlb,本文中所介绍的一些代码现在已被修改优化,但并不影响对整体机制的理解。
由于 swiotlb 底层不可避免要进行数据拷贝,在处理大型数据时存在天然的不足。这种情况下,零拷贝方案成为了更优的进化方向。通过 IOMMU 硬件的地址映射支持,或者采用共享内存页所有权转移等机制,数据可以直接在设备与虚拟机内存之间流动,从而彻底消除弹跳缓冲区带来的中间损耗。
参考
DMA and swiotlb — The Linux Kernel documentation Restricted DMA [LWN.net] [PATCH v13 00/12] Restricted DMA [LWN.net] Measuring and Optimizing the Performance of the Android Virtualization Framework [v2] swiotlb performance optimizations | Patchew Bug #1971701 “Azure: swiotlb patch needed for CVM” : Bugs : linux-azure package : Ubuntu